ALBのログをAthenaで分析する方法は、公式ドキュメントに記載があるのですが、この手順でデータベースを作成すると、日付の条件を入れて検索したいとき、大量のデータをスキャンしてしまい、遅い上にお金がかかるという問題に遭遇します。
そこでおすすめしたいのが、データベース作成時にパーティションを作っておくことです。
・・・という記事を書こうと思っていたのですが、このドキュメントでもパーティションを利用するようになっていたので、記事の役割が死にました。
なので、この記事は削除しようかとも思ったのですが、パーティションの切り方が公式と違っていたので、一応投稿して供養しておきます。
Athenaテーブルの作成
Athenaで適当なデータベースを選択、または作成したら、以下のクエリを実行してテーブルを作成します。
実際に作成する場合は、SQLのこれらの箇所を修正してください。
- LOCATION: 's3://
ALBのログが保存されているS3バケット名/AWSLogs/AWSアカウントID/elasticloadbalancing/リージョン/' - TBLPROPERTIES
- projection.date_time.range:ログを取り始めた日から(サンプルクエリでは1年前にしている)
- storage.location.template:LOCATIONと同じバケットのパス+
${date_time}
テーブル作成クエリ
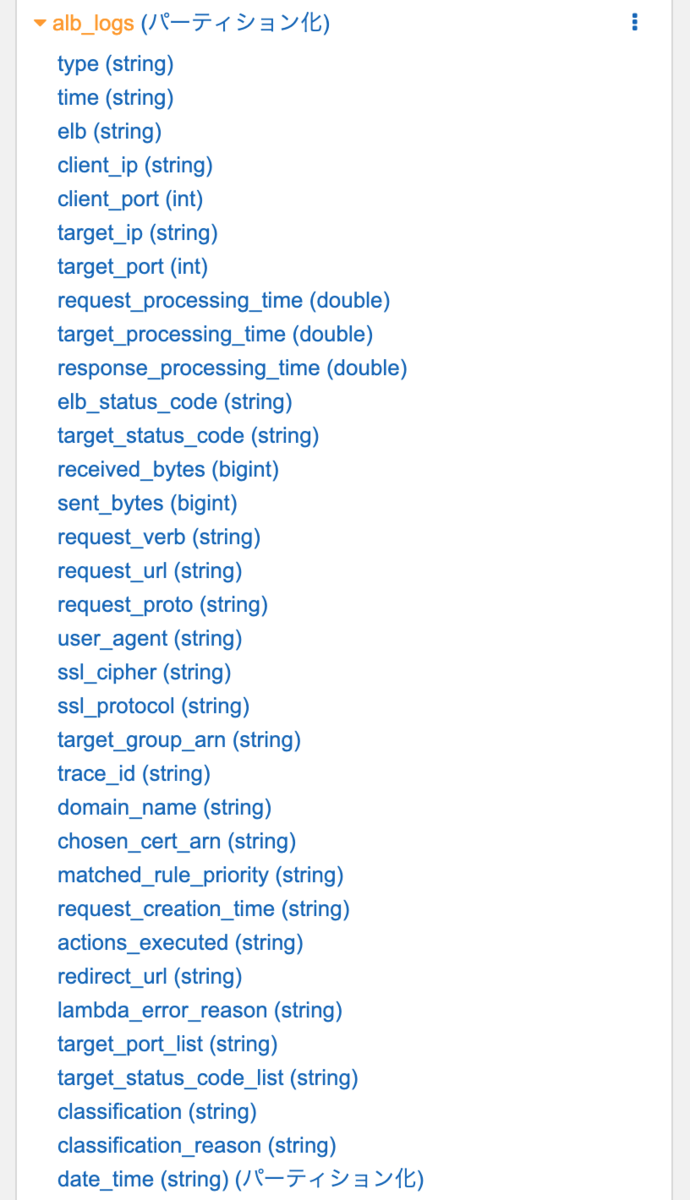
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs ( type string, time string, elb string, client_ip string, client_port int, target_ip string, target_port int, request_processing_time double, target_processing_time double, response_processing_time double, elb_status_code string, target_status_code string, received_bytes bigint, sent_bytes bigint, request_verb string, request_url string, request_proto string, user_agent string, ssl_cipher string, ssl_protocol string, target_group_arn string, trace_id string, domain_name string, chosen_cert_arn string, matched_rule_priority string, request_creation_time string, actions_executed string, redirect_url string, lambda_error_reason string, target_port_list string, target_status_code_list string, classification string, classification_reason string) PARTITIONED BY ( `date_time` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1', 'input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"') LOCATION 's3://my_log_bucket/AWSLogs/1111222233334444/elasticloadbalancing/ap-northeast-1/' TBLPROPERTIES ( 'classification'='csv', 'projection.date_time.format'='yyyy/MM/dd', 'projection.date_time.interval'='1', 'projection.date_time.interval.unit'='DAYS', 'projection.date_time.range'='2020/06/16,NOW', 'projection.date_time.type'='date', 'projection.enabled'='true', 'projection.pvid.type'='injected', 'storage.location.template'='s3://my_log_bucket/AWSLogs/1111222233334444/elasticloadbalancing/ap-northeast-1/${date_time}') ;
このやり方のメリット
このテーブルを利用する場合のメリットは大きく2つあります。
- S3バケットのデータスキャン範囲の限定
- テーブルの定期更新が不要
解説
このクエリで作成したテーブルにはdate_time (string) (パーティション化)というカラムが追加されています。
このカラムを検索クエリに含めた場合、AthenaがスキャンするS3バケットのフォルダは、カラム条件の範囲だけになります。
例えば、2021/06/15のログから調査したい場合は、以下のようなクエリ(6/15でアクセスの多いIPアドレスを確認)にすることができます。
SELECT COUNT(request_verb) AS count, request_verb, client_ip FROM alb_logs WHERE date_time = '2021/06/15' GROUP BY request_verb, client_ip;
注意したいのは、ALBで扱う日付はUTCになっているので、JSTで確認したい場合は日を跨いで指定する必要があることです。 範囲の指定はIN句でもBETWEENでも大丈夫なので、お好きな方でOKです。
時間を厳密に指定したい場合は、timeカラムを利用してください。
例えば、先程のクエリをJSTの6/15とした場合は以下のようになります。
SELECT COUNT(request_verb) AS count, request_verb, client_ip FROM alb_logs WHERE date_time in ('2021/06/14', '2021/06/15') AND (parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') BETWEEN parse_datetime('2021-06-14-15:00:00','yyyy-MM-dd-HH:mm:ss') AND parse_datetime('2021-06-15-14:59:59','yyyy-MM-dd-HH:mm:ss')) GROUP BY request_verb, client_ip;
また以前までのテーブルであれば、作成後はデータのスキャン範囲が自動的に増えなかったのですが、
このテーブルはprojection.date_time.rangeで範囲の終端にNOWを指定しているため、テーブルを更新し直さなくても常に最新のログまで検索することができます。
公式ドキュメントのパーティションとの差分
公式ドキュメントではフォルダのパーティションを、年、月、日で数値管理にしているので、クエリを書く際は年月日をそれぞれ分けて指定することになります。 また、rangeも2020,2021としているため、2022年以降のログはテーブルを更新し直す必要があります。
そういった違いを考えると、この記事にも一定の意味があったのかなと思えなくもないですね。